Paper | 工gin師 YT解說| Control-Net源码分析及实践篇
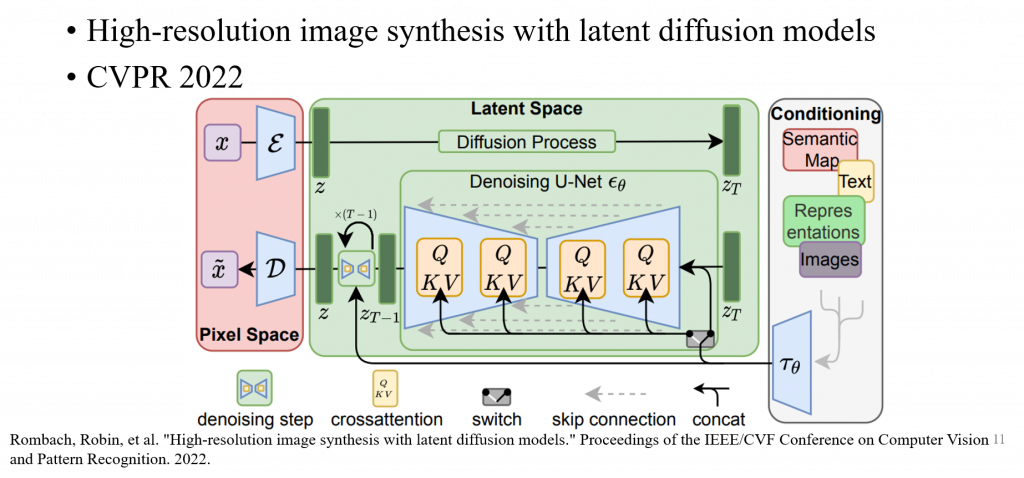
High-Resolution Image Synthesis with Latent Diffusion Models
Sorry, 我忘記介紹SD了
傳統的擴散模型存在一些缺陷,例如無法有效地控制生成的內容,以及訓練時間過長。
為了解決這些問題,Stable Diffusion提出了一種新的擴散模型。
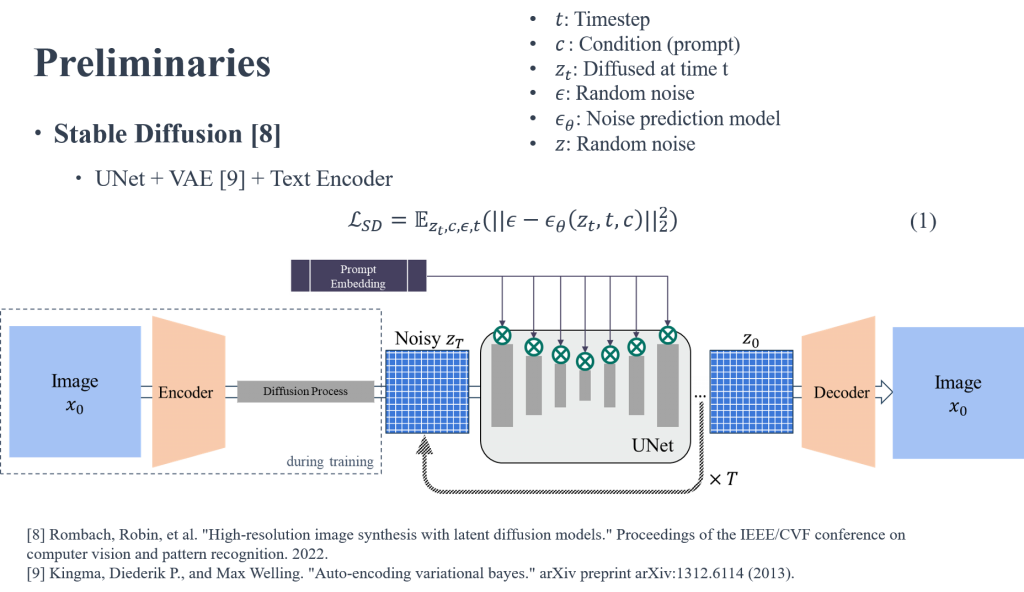
主要由兩個部分組成:VAE和一個 UNet。VAE 負責將圖像encoding成低維的latent space,並在latent space進行Diffusion 的運算,同時以Cross attention方式,把額外的條件在Unet的每一層特徵進行融合,達到控制生成。
而Loss將變成上述的公式
由模型預測的noise和Ground truth的noise 互相計算L2 LOSS。
在原始論文的架構圖可以看到 SD 本身概念是可以接除了文字以外的條件,但大家好像都沒有 train 他,單純把SD拿來當T2I的模型
不過這也是有原因的
Stable Diffusion v1 版本的模型單次訓練便需要150000 個A100 GPU Hour。
Stable Diffusion的預訓練採用的LAION-5B數據集共5850億個圖片文本對,需要240TB儲存空間,再結合模型的複雜性,顯然完整預訓練的成本極高:Stable Diffusion的Stability團隊花費超過5000萬美元部署了4,000塊A100 GPU。
另外,我也對T2I Diffusion Model 的整個研究方向進行簡單的分析,以下link供大家參考(但可能會有誤)
https://gitmind.com/app/docs/mg5jmm7c
現有的方法提供的生成控制程度太有限了
不太想要只有一個文字的控制,希望能有多個控制,並將多種控制組合成一起,產生的結果就能符合期待。
HuggingFace Demo
ControlNet 是一種使用額外的條件輸入來控制擴散模型的神經網路結構,它可以提供更細緻和靈活的控制效果。
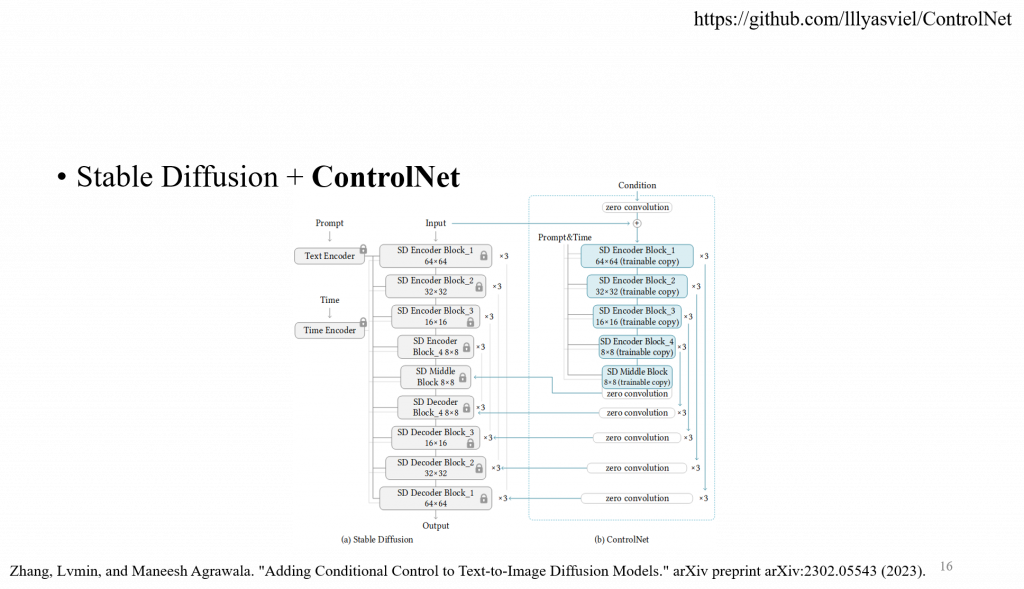
一個 task-specific 需要針對不同任務去訓練一個 controlnet,可以在個人設備進行訓練。
他們後面有在做一些改進,輕量化 ControlNet 移除掉某幾層網路,這樣就不需要大量的記憶體。
另外實驗的時候有發現一個現象: The sudden convergence phenomenon,指在 ControlNet 的訓練過程中,觀察到模型沒有逐漸學習控制條件,而是突然成功地就學會生成與條件相符的高品質圖像。通常會在不到 10K 個step 的時候發生,但他們也不知道為什麼會突然有這個現象。
ControlNet 需要針對不同的任務進行訓練,因此需要大量的訓練資料和計算資源,進行訓練需要46GB的空間,並且需要針對每個condition進行訓練,因此需要大量的標記資料,以及針對不同任務進行專門的調整和優化。它需要大量的記憶體空間,因為它本身就是一個latent diffusion模型,進行測試和訓練需要46GB的空間,並且需要針對每個condition進行訓練,因此需要大量的標記資料。
ControlNet
Reference: https://xiqiao.blog.csdn.net/article/details/129152978
有人用 ControlNet 架構去改良
Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models
他可以靈活地組合不同類型的控制條件,例如邊緣圖、深度圖、seg mask、CLIP圖像embedding等,來指導圖像生成的過程。只需要在預訓練的T2I擴散模型上微調兩個額外的Adapter,一個是局部控制Adapter,一個是全局控制Adapter,而不需要從頭開始訓練一個新的模型,這樣可以節省大量的計算資源和時間。
但我覺得training的時候又要炸記憶體,就算模型是frozen的狀況下也要回傳梯度紀錄/更新,所以GPU還是需要吃掉資源

Reference: https://zhuanlan.zhihu.com/p/634540195


 iThome鐵人賽
iThome鐵人賽